이번에는 타이타닉 Data Set을 Decision Tree 모델을 사용해서 예측을 진행해보겠다.
근데 하다보니 느낀건데 전처리 과정이 다 똑같애서 그냥 모델만 바꿔 끼는거 같애서 너무 쉽게 구현하는거 아닌가??? 싶었지만 해보면서 직접 해당 모델들이 어떤 특성을 가지고 있는지 그리고 그 사용법을 아는 것에 의의를 찾기로 했다.
Decision Tree??
데이터를 분류하거나 회귀 분석을 수행하는 머신러닝 알고리즘이다.
- 결정 트리는 나무 형태의 그래프 모델로, 데이터의 특성을 기반으로 질문을 통해 결정을 내린다.
- 루트 노드에서 시작하여 각 내부 노드에서 특성에 대한 테스트를 수행하고, 그 결과에 따라 다른 경로로 이동한다
- 최종적으로 리프 노드에 도달하면 그 노드가 예측 결과(클래스 또는 값)을 제공한다
장점
- 해석하기 쉽고 시각화가 가능하다
- 데이터 전처리가 적게 필요하다(정규화, 더미 변수 등이 필수는 아님)
- 수치형과 범주형 데이터 모두 처리 가능
Classification and Regression Tree -> CART - series : 의사결정트리에서 Boosting까지
기존 Decision Tree 을 계속해서 발전시켜서 XGboost,Light GBM 까지 간 것이다.
의사결정 트리 모델에서 가지치기(Pruning)은 과적합(Overfitting)을 막기 위한 기법이다.
근데 여기서 타이타닉 데이터셋을 기준으로 루트노드가 어떤 것을 설정될까??
그 기준은 바로 불순도를 최대로 감소시키는 속성을 선택한다. 그리고 그 불순도 측정 방법이 총 3가지가 있으며
정보 이득(Information Gain), 지니 불순도(Gini Impurity), 엔트로피(Entropy) 이렇게다.
기본적으로는 지니 불순도로 지정되어 있고 따로 설정 할 수 있긴하다.
# 지니 불순도 사용 (기본값)
model = DecisionTreeClassifier(criterion='gini', random_state=42)
# 또는 엔트로피 사용
# model = DecisionTreeClassifier(criterion='entropy', random_state=42)
하면서 추가적으로 seaborn을 이용해 성별과 생존을 시각화 해보았다.


결과는??

놀랍게도 점수가 저번 포스트인 0.76점 보다 더 떨어졌다. 전처리가 잘못된 것일까??
다른 의사결정 트리 기반 모델들 RandomForest, XGBoost, LGBM 을 사용해보자.

딱히 뭐 대단한 예측 정확도를 보여주지는 않는다. 물론 캐글에서 정답을 다 맞추신 분들도 있으니 내 데이터 전처리과정이나 결측치 처리가 잘못되었겠지만!!
구글링 결과....
트리 기반 모델은 일반적으로 선형 모델보다 뛰어난 성능을 보이지만, 적절한 하이퍼파라미터 튜닝과 특성 엔지니어링이 없으면 그 이점이 발휘되지 않을 수 있다!!!
더 궁금해서 데이터로 동일한 전처리 과정을 거치고 Lasso와 Ridge 모델을 사용해봤다. 물론 0.5를 임계값으로 잡고 0.5이상이면 생존 미만이면 사망으로 처리해서
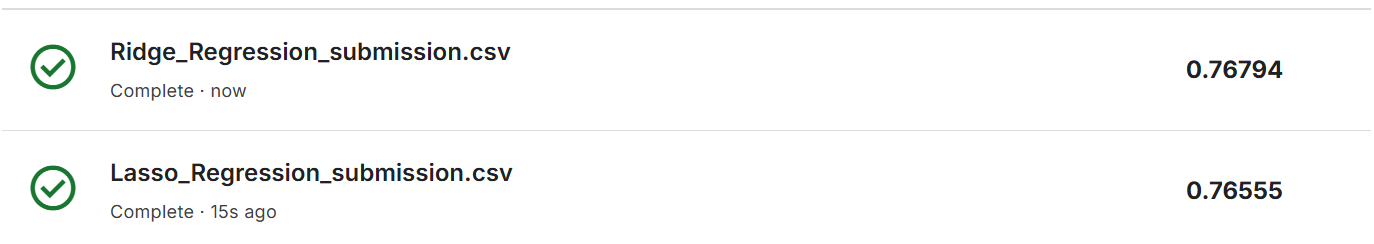
썩 좋은 점수는 아니다
마지막으로 Decision Tree와 Random Forest 모델에
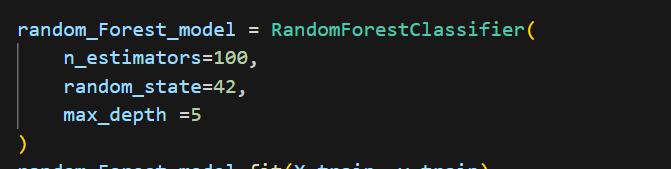
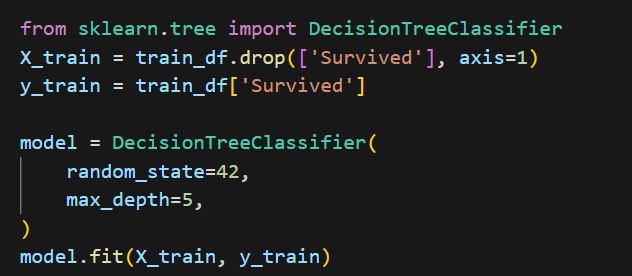
이런식으로 max_depth와 RandomForest의 경우 n_estimators = 100을 넣어주었다.
여기서 잠깐
max_depth?? 결정 트리의 루트에서 리프 노드까지의 최대 경로 길이
n_estimators?? 랜덤 포레스트에서 생성할 결정 트리의 개수. 값이 커질수록 더 안정적이고 정확한 결과를 얻을 수 있지만 계산 비용이 증가한다. 값이 작으면 계산은 빠르지만 모델의 성능과 안정성이 떨어질 수 있다. 보통 100~500을 많이 쓴다고한다. 예측시 모든 트리의 평균(회귀) 또는 다수결로 결정한다(분류)

위 이미지와 같이 조금 더 나은 결과값을 뱉어냈다.
과연 그렇다면 n_estimators = 500 일 때에는??

조금 더 좋아졌다!!!
궁금해서 5만까지 넣어봤다.
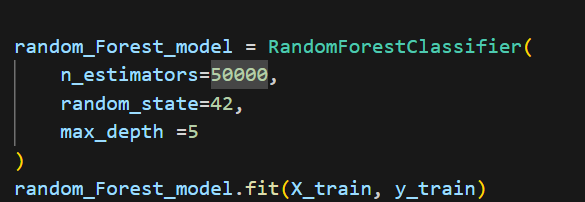
ㅋㅋ 1분이 넘어도 학습이 안끝나서 검색해보니 너무 오래 설정 하면 몇 시간 몇일이 걸릴 수도 있다고 한다.
근데 1분 44초만에 끝났다!! 아무래도 타이타닉 데이터셋 자체가 단순하고 심플해서 금방 끝난듯 !!

딱히 더 좋아지진 않는듯.
다양한 모델들을 가지고 타이타닉 데이터 셋을 예측하고 분석해본 결과....
역시 데이터의 특성에 맞게 전처리를 해주고 모델을 선택하는게 가장 중요한 것 같다.
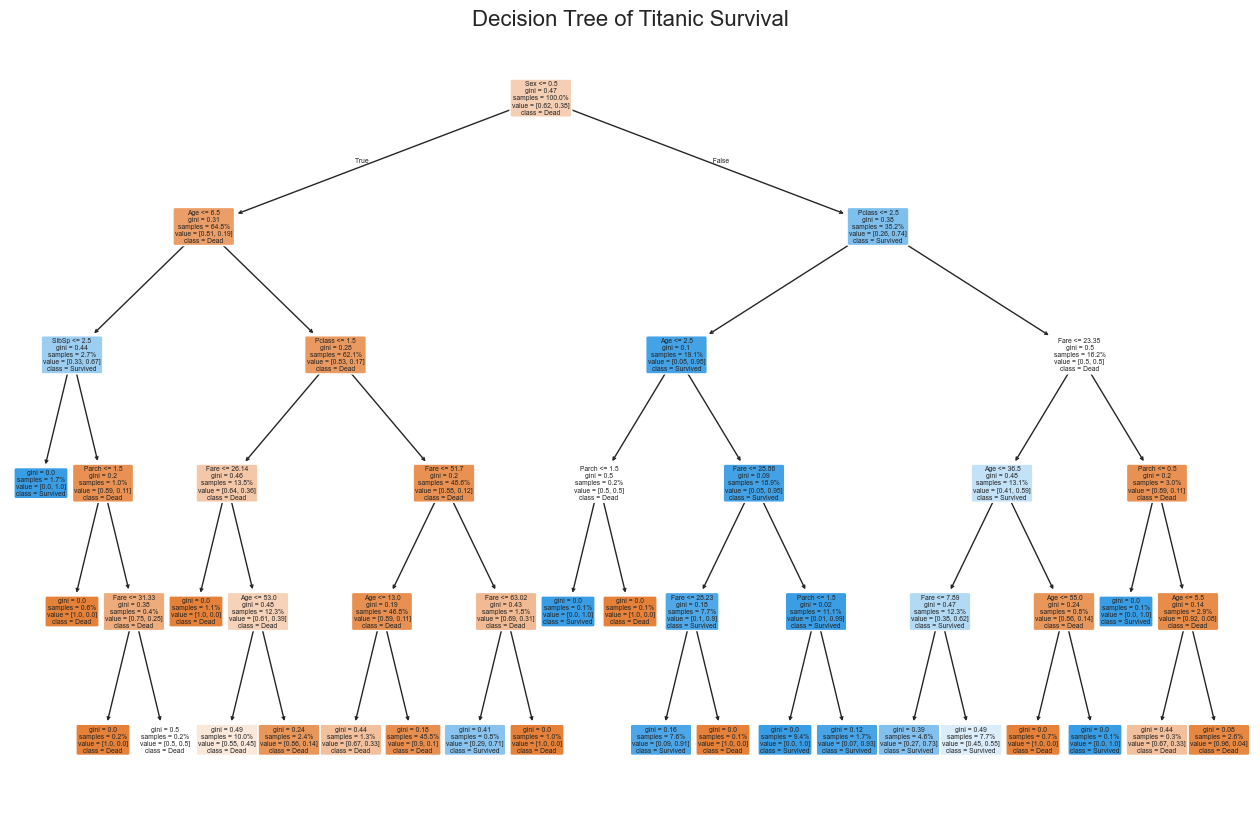
마지막으로 트리 시각화를 해보고 이 포스트를 마무리 하겠다.
'SKALA > AI' 카테고리의 다른 글
| 프로필 사진 지브리 스튜디오 스타일로 변경 (0) | 2025.03.24 |
|---|---|
| 생성형 AI 및 Prompt Engineering (1) | 2025.03.21 |
| 딥러닝 아키텍처 개념, CNN, RNN, LSTM, Transformer 등등... (0) | 2025.03.17 |
| 타이타닉 Data Set, Logistic Regression+ 선형 회귀와 비교 (0) | 2025.03.12 |
| 타이타닉 Data Set, Linear Regression 결과 (0) | 2025.03.11 |
