Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
옆자리 짝꿍이 알려준 Data 분석을 실습할 때 사용할 수 있는 데이터 셋을 받을 수 있는 사이트 캐글이다.
이 사이트에서 받은 타이타닉 Data Set으로 각종 모델들을 학습하고 어떤 모델이 가장 뛰어난 성능을 보였는지 확인 해 볼 예정이다.
🚢 캐글(Kaggle) 타이타닉 데이터셋이란?🚢
캐글(Kaggle)에서 제공하는 "Titanic: Machine Learning from Disaster" 데이터셋. 1912년 4월 15일 침몰한 타이타닉호 승객들의 생존 여부를 예측하는 머신러닝 입문용 데이터셋이다.
→ 즉, 승객의 나이, 성별, 좌석 등급 등을 기반으로 생존 여부(Survived)를 예측하는 문제!
타이타닉 데이터셋에는 train.csv와 test.csv가 있다.
1️⃣ train.csv (학습 데이터)
- 머신러닝 모델을 훈련하는 데 사용
- Survived 컬럼(목표 변수)이 있음 (1 = 생존, 0 = 사망)
2️⃣ test.csv (테스트 데이터)
- 실제 예측을 수행하는 데이터
- Survived 컬럼이 없음 (이 값을 예측하는 것이 목표)
컬럼 설명
- Survived : 생존 여부 (0 = 사망, 1 = 생존)
- Pclass : 티켓 클래스 (1 = 1등석, 2 = 2등석, 3 = 3등석)
- Sex : 성별
- Age : 나이
- SibSp : 함께 탑승한 자녀 / 배우자 의 수
- Parch : 함께 탑승한 부모님 / 아이들 의 수
- Ticket : 티켓 번호
- Fare : 탑승 요금
- Cabin : 수하물 번호
- Boat : 탈출한 보트가 있다면 boat 번호
- Embarked : 선착장 (C = Cherbourg, Q = Queenstown, S = Southampton)
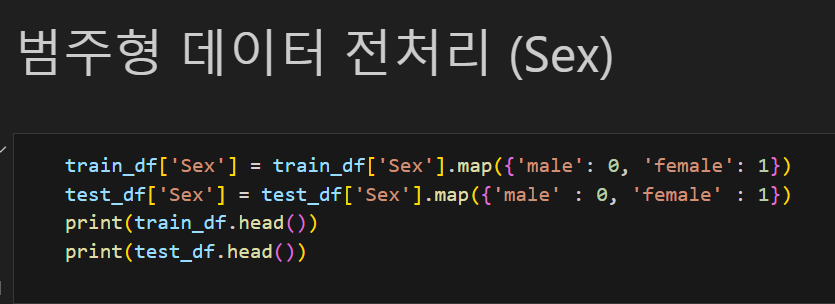
여기서 결측치가 있는 컬럼을 확인하고 처리해주고, 범주형 데이터를 숫자로 변경하고(One-Hot Encoding)
모델에 학습시켜서 test.csv로 predict하면 끝!!
코드 설명을 보기 전에 간단하게 선형회귀가 무엇인지 확인해보자!!
선형 회귀 (Linear Regression) & 다중 선형 회귀 (Multiple Linear Regression)
선형 회귀는 데이터를 기반으로 두 변수(또는 여러 변수) 사이의 관계를 선형 함수로 모델링하는 방법
- 선형 회귀 (Simple Linear Regression): 하나의 독립 변수(Feature)로 종속 변수(Target)를 예측
- 다중 선형 회귀 (Multiple Linear Regression): 여러 개의 독립 변수를 사용하여 종속 변수를 예측

선형 회귀는 현실적인 한계가 있다
- 데이터가 반드시 직선관계를 가져야 한다
- 이상치(Outlier)에 민감함
- 비선형 관계(곡선 형태)를 표현하기 어려움
그래서 사실 분류 문제를 해결할 땐 로지스틱 회귀분석을 사용한다고 하지만 나는 이것저것 배워보면서 차이가 뭔지 직접 알아보는게 목표이기에 그건 신경쓰진 않는다.
데이터 분석을 위한 각종 라이브러리들을 불러온다
개인적으로 이 부분을 잘 파악해주는게 중요하다고 생각한다!!
상식적으로 이름이 과연 생존율에 영향을 끼칠까..??
아니면 티켓번호가?? 승선한 곳이 ?? 이걸 파악하는 것도 데이터 분석가의 역량이라고 생각한다
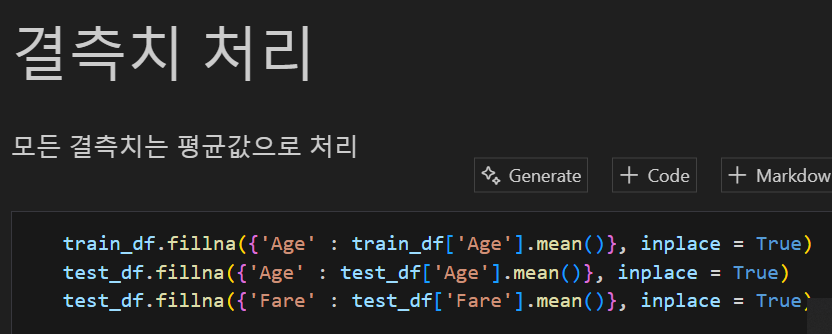
사실 이 부분은 맞는지는 모르겠다. 모든 결측치를 평균값으로 하는게 맞나??? 라는 생각이 들었지만 사실
선형회귀가 무엇인지 배우는 거에 중점을 둔 실습이기에.... Kaggle 타이타닉 데이터 셋 1등할 것도 아니고 ㅎ
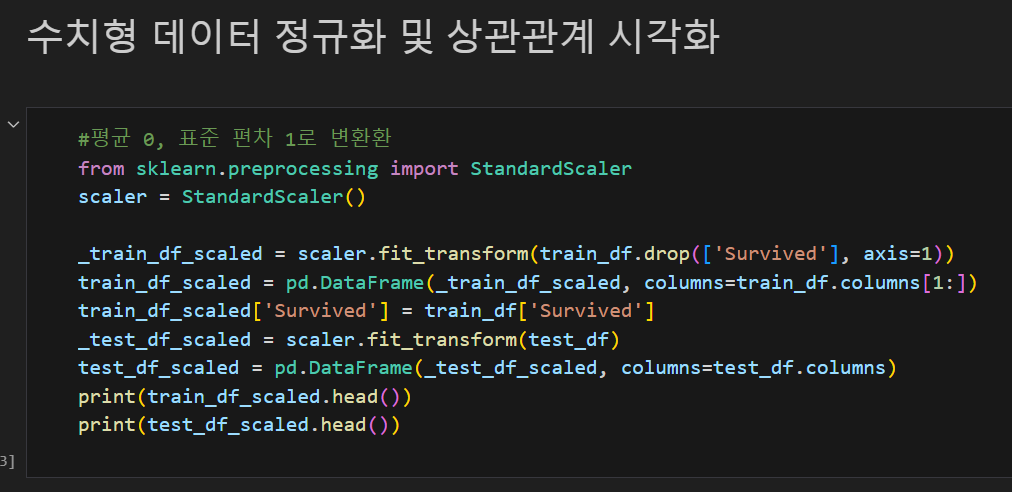
여기서 정규화는 왜 필요한가??
모든 항목들이 같은 값의 범위를 갖고 있지는 않다... 예를 들어 male이면 1인데 age가 50이다.
이런 항목이면 age가 엄청난 가중치를 갖게 되기에 모든 항목이 평균 0 표준편차 1을 갖게 해야한다.
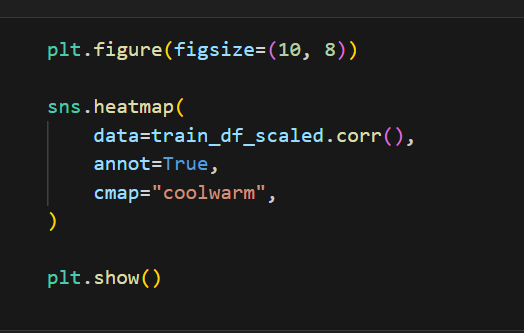
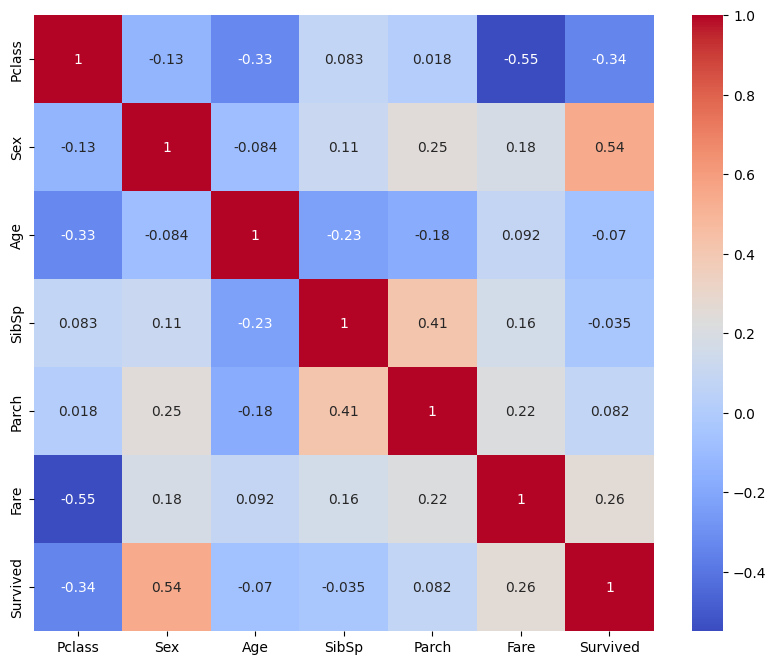
시각화는 데이터 분석에서 매우 중요하다고 생각한다. 예상했던 대로 Sex가 가장 생존율과 높은 상관관계를 가지고 있다. 그때는 여성, 어린이, 노약자 먼저 구명보트에 태웠으니!! 근데 의외로 Age가 별 영향을 안 끼쳤네??
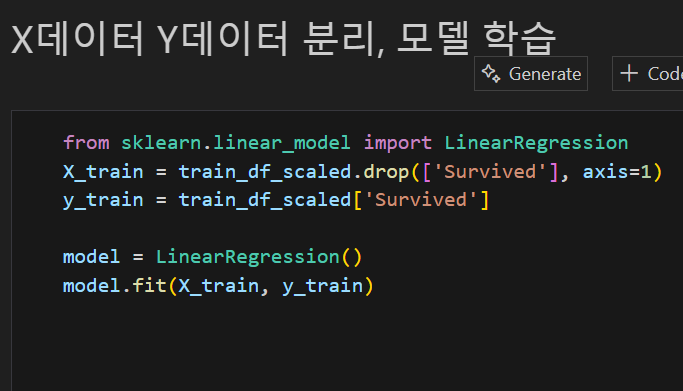
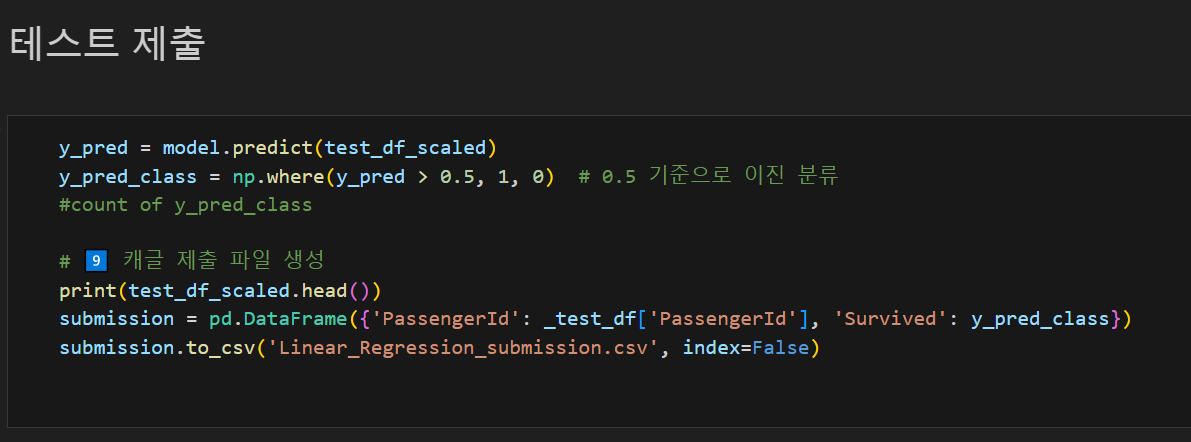
마지막으로 모델을 학습시키고 학습된 모델을 가지고 test.csv를 넣어서 예측값을 받는다. 이제 캐글에 제출하면 아래오 같이 점수가 나온다!!
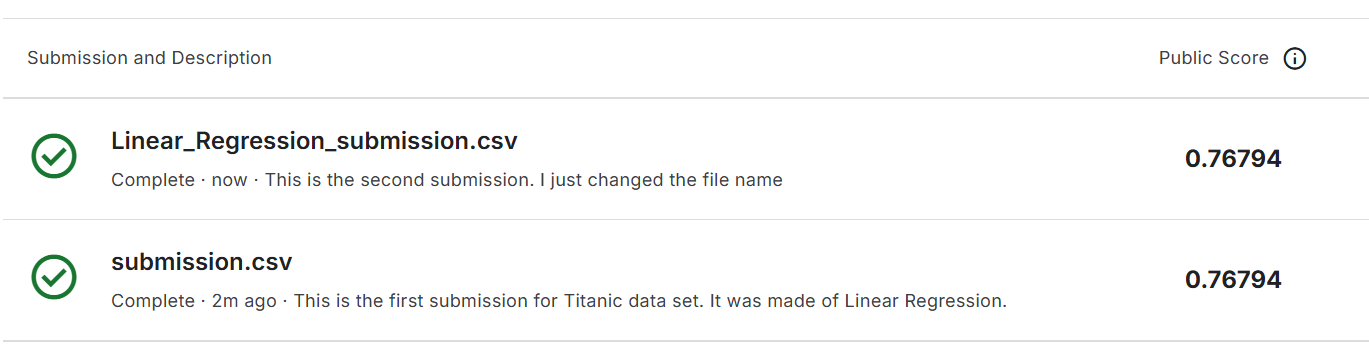
처음 한 거 치곤 꽤 만족스러운 점수가 나왔다!! 사실 선형회귀는 별로 분류에는 좋지 않은 모델이라고 하지만 정말 말 그대로 학습에 중점을 둔 실습이었기에 다음에는 로지스틱 회귀분석으로 진행 해 볼 예정이다!!
