반응형
기존 RAG의 한계를 극복하기 위해 Graph RAG라는 것이 고안되었다.
지식그래프기반의 RAG로 일반적인 벡터검색을 기반한 RAG보다 엔티티간의 관계를 따라 가다보면 더 정확하고 상세한 답변에 도달 할 수 있다.
지식그래프
개체, 사건 또는 개념과 같은 실체에 대한 상호 연결된 설명 모음을 뜻함
Graph RAG vs 일반 Vector RAG
일반 RAG 특징
- Dense retriever (예: FAISS, BM25 등)을 통해 관련 문서를 가져옴
- 선택된 문서를 LLM에게 전달하여 답변 생성
- 문서 간 관계를 고려하지 않음 (독립적 정보 취급)
Graph RAG 특징
- 문서 간 개체(entity), 개념(concept), 관계(relationship)를 추출해 Knowledge Graph를 구성
- LLM은 단순한 문서 조각이 아닌, 연결된 지식을 기반으로 답변 생성
- 문맥 흐름, 관계 기반 추론이 더 정밀
Graph RAG 장점
- 문맥 유지력 향상
- 정밀한 검색
- 추론 가능 : A -> B -> C 관계에서 A와 C를 연결하는 추론 가능
- 지식 확장성 : 그래프 기반이기 때문에 지식이 구조적으로 확장 가능
Graph RAG 한계
- 구축 난이도
- 처리 시간 : 그래프 탐색 + LLM 처리로 응답 시간이 길어질 수 있음
- 관계 추출 한계 : 관계 추출 정확도가 낮으면 잘못된 그래프 생성
Vector 기반 RAG를 써야 할 때
- 빠르게 시작하고 싶을 때
- 정보가 독립적인 경우
- 간단한 질의응답이 주 목적일 때
- 빠른 응답속도가 중요한 경우
벡터 검색은 대부분의 라이브러리에서 최적화되어 있어서 응답 시간이 빠르기 때문에, 실시간 응답이 필요한 챗봇이나 검색 시스템에 적합
Graph RAG를 써야 할 때
- 문서 간의 관계가 중요한 경우
예를 들어 어떤 사람이 어떤 사건에 관여했고, 그 사건이 또 다른 사건과 연결되는 등 복잡한 연결 관계가 있는 경우에는 Graph RAG가 훨씬 강력 - 지식 간의 연결을 통해 추론이 필요한 경우
“A가 B를 만들었고, B가 C에 영향을 준다면 A는 C와 어떤 관계가 있지?” 같은 간접적인 추론이 필요한 질문에 적합 - 정보량이 많고 구조적인 정리가 필요한 경우
대규모의 논문, 법률 문서, 과학 지식처럼 방대한 데이터에서 의미 있는 연결고리를 추출해야 하는 상황에서 유리 - 사용자가 자주 맥락을 따져 질문할 때
단순한 사실 조회가 아니라, "이 사람이 왜 그런 선택을 했지?" 같은 배경 추론이 필요한 경우.
아래는 LangChain이 공개한 Graph RAG의 처리 흐름

결국 무슨 수를 써서든 문서에서 엔티티를 추출해서 Graph를 구축하고 RAG를 하는 것이다!
당연히 GraphDB( ex : Neo4j, Amazon Neptune) 등을 이용해서 DB를 사용해도 된다.
하지만 나는 그렇게 까지 하기에는 시간이 없으니 그냥 간단하게 파이썬 라이브러리로 실습만 하고 끝낼 것이다
NetworkX와 spaCy 활용 예제
# 1. 샘플 문서 생성 - 영어로 된 텍스트 (관계 흐름: A -> B -> C)
sample_texts = [
"GPT-4 is an advanced language model developed by OpenAI.",
"Sam Altman is the CEO of OpenAI and oversees the development of GPT models.",
"Microsoft has invested billions of dollars in OpenAI since 2019.",
"Claude is a competing AI model created by Anthropic."
]
각종 라이브러리를 불러들이는 import문과 OpenAI사의 api키가 필요하다
# 2. spaCy를 활용한 개체와 개체간 관계 추출
def build_simple_graph(texts):
# spaCy 모델 로드
print("spaCy 모델을 다운로드합니다...")
try:
nlp = spacy.load("en_core_web_sm") # 영어 모델 사용
except:
print("en_core_web_sm 모델 다운로드 중...")
spacy.cli.download("en_core_web_sm")
nlp = spacy.load("en_core_web_sm")
# 그래프 생성
G = nx.DiGraph()
# 텍스트 처리
for text in texts:
doc = nlp(text)
# 문서에서 명사 추출
entities = []
for token in doc:
if token.pos_ in ["NOUN", "PROPN"]: # 명사와 고유명사
entities.append(token.text)
# 간단한 구조: 문장 안의 첫 번째 명사와 나머지 명사들을 연결
if len(entities) >= 2:
source = entities[0]
# 그래프에 노드 추가
if not G.has_node(source):
G.add_node(source)
# 첫 번째 명사를 다른 명사들과 연결
for target in entities[1:]:
if not G.has_node(target):
G.add_node(target)
# 주요 동사 찾기
verb = "related_to" # 기본 관계
for token in doc:
if token.pos_ == "VERB":
verb = token.lemma_
break
# 관계 추가
G.add_edge(source, target, relation=verb)
return G
# 그래프 생성
graph = build_simple_graph(sample_texts)
# 그래프 시각화
plt.figure(figsize=(10, 8))
pos = nx.spring_layout(graph, seed=42)
nx.draw_networkx_nodes(graph, pos, node_size=700, alpha=0.8)
nx.draw_networkx_labels(graph, pos, font_size=10)
nx.draw_networkx_edges(graph, pos, width=1.0, alpha=0.7, arrows=True, arrowsize=15)
# 엣지 레이블 추가
edge_labels = {(u, v): d["relation"] for u, v, d in graph.edges(data=True)}
nx.draw_networkx_edge_labels(graph, pos, edge_labels=edge_labels, font_size=9)
plt.axis("off")
plt.title("간단한 지식 그래프")
plt.tight_layout()
plt.show()
위와 같이 그래프를 시각화 해서 볼 수 있다
마지막으로 제일 중요한 그래프 기반 검색 함수
def graph_search(query, graph, max_hops=2):
"""그래프에서 질문과 관련된 경로 탐색"""
results = []
query = query.lower()
# 그래프에서 노드 찾기
for node in graph.nodes():
if node.lower() in query:
# 발견된 노드에서 max_hops 단계까지 탐색
paths = []
for target in graph.nodes():
if node == target:
continue
try:
# 최단 경로 찾기
path = nx.shortest_path(graph, source=node, target=target)
if len(path) <= max_hops + 1: # +1은 시작 노드를 포함하기 때문
# 경로의 관계 포함
path_with_relations = []
for i in range(len(path) - 1):
source = path[i]
dest = path[i+1]
relation = graph.edges[source, dest]['relation']
path_with_relations.append((source, relation, dest))
paths.append(path_with_relations)
except nx.NetworkXNoPath:
continue
if paths:
results.extend(paths)
# 결과 포맷팅
formatted_results = []
for path in results:
path_str = " -> ".join([f"{s} --[{r}]--> {d}" for s, r, d in path])
formatted_results.append(path_str)
return formatted_results
마지막으로 두 RAG를 비교하는 함수를 만들어주고 적절히 프롬프트를 만들어준다
여기서 중요한게 할루시네이션을 안 만들게 모르겠으면 모르겠다고 얘기하게 해야한다

결과
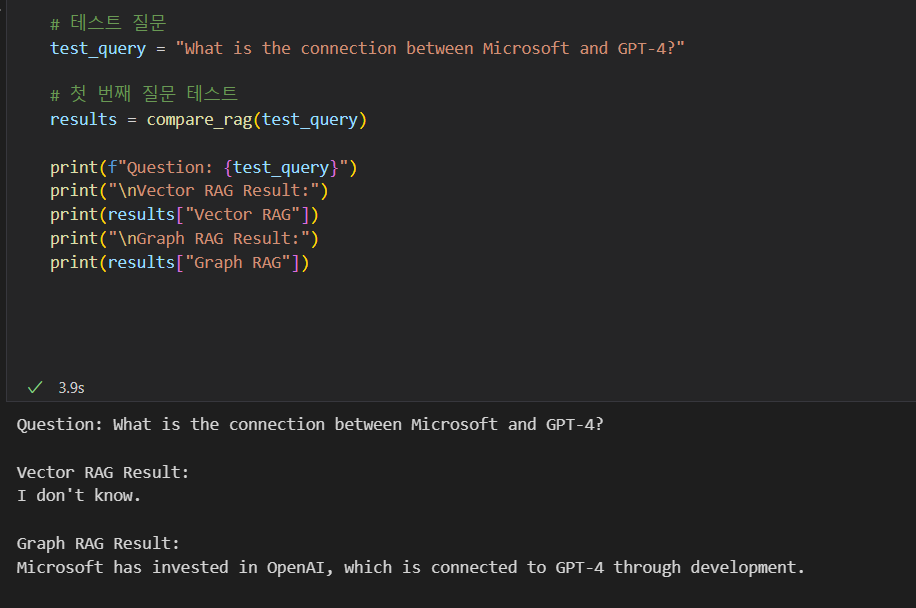
사실 뜻하는 대로 결과가 안나와서 질문을 몇 번이고 바꾸었다. 그냥 이런 결과를 기대해서 이런 코드를 만들었고 실습을 해보았다~~ 정도로만 하고 넘어가려 한다.
반응형
'SKALA > AI' 카테고리의 다른 글
| AutoGen (0) | 2025.04.24 |
|---|---|
| Cross Validation (0) | 2025.04.23 |
| 앙상블(Ensemble) (0) | 2025.04.21 |
| 네이버 뉴스 RAG 실습(3) - Prompting 및 RAG 구축 (2) | 2025.04.11 |
| 네이버 뉴스 RAG 실습(1) - WebBaseLoader (0) | 2025.04.09 |
